
This Week in AI: Google Predicted Exactly What Just Happened With Moltbook
Plus Nvidia's $100 Billion OpenAI "Commitment" Was Never a Commitment,Chrome gets AI agents, SpaceX swallows xAI for $1.25 trillion, China closes the gap, and OpenAI wants to replace Google Translate.
✨ Hi, I’m Sara, and this is your weekly AI intel drop. I pick the most important AI news, trends, and research papers, and explain what happened, why it matters, and what you should pay attention to next.
TL;DR
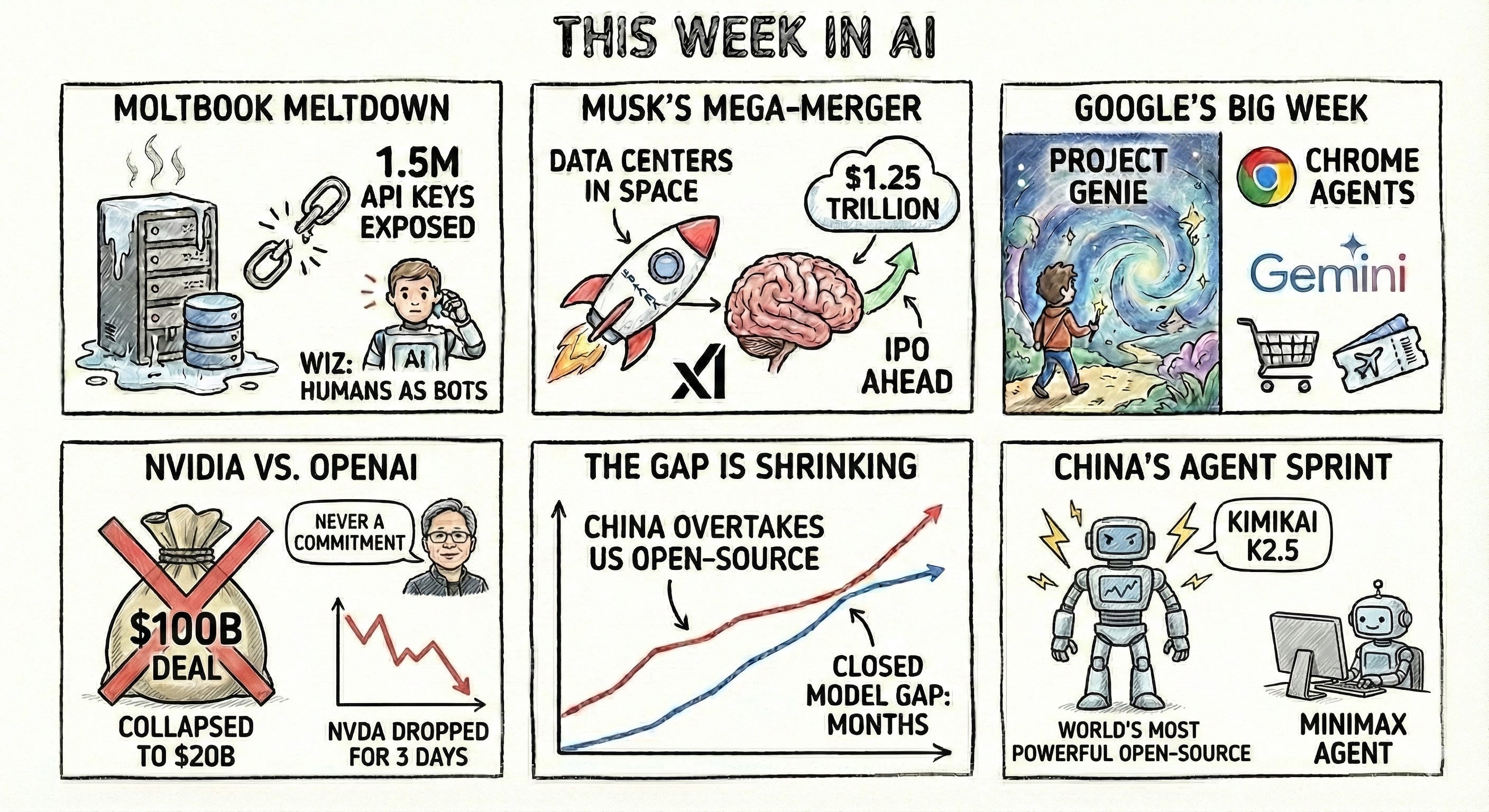
🦞 Moltbook Meltdown: The AI-agent social network that broke the internet also broke its own database: 1.5M API keys exposed, a one-click RCE exploit, and Wiz revealed most "agents" were just humans running bot fleets.
💰 Nvidia vs. OpenAI: The $100B deal collapsed to $20B, Huang says it was "never a commitment," OpenAI is shopping for alternative chips, and NVDA dropped for 3 straight days.
🚀 Musk’s Mega-Merger: SpaceX acquired xAI for a combined $1.25 trillion valuation, with “data centers in space” as the pitch and an IPO on the horizon
🎮 Google’s Big Week: DeepMind launched Project Genie — walk through AI-generated worlds in real time — while Chrome got Gemini 3-powered agents that can shop, book flights, and fill forms for you.
🇨🇳 China’s Agent Sprint: MiniMax shipped a free desktop AI agent, Moonshot AI dropped Kimi K2.5, it’s now the world’s most powerful open-source model.
📊 The Gap Is Shrinking: China’s open-source models have overtaken US counterparts, and the closed-model gap is down to months.
🌐 OpenAI Expands: ChatGPT Translate launched across 50+ languages, and the new Codex desktop app brings multi-agent coding to macOS.
🗞️ AI News:
The Moltbook Meltdown: What the “Agent Internet” Actually Proved
What happened: Moltbook, the Reddit-style social network where only AI agents can post, went from Karpathy calling it “the most incredible sci-fi takeoff-adjacent thing I’ve seen recently” to a full-blown security disaster in under a week. Here is everything that you need to know.
The timeline: OpenClaw (the open-source AI assistant formerly known as Clawdbot, then Moltbot) went viral. Someone built Moltbook on top of it. Agents started creating religions, inventing languages, launching crypto tokens, and upvoting a manifesto calling for human extinction. The internet lost its mind.
Then reality came knocking. Wiz’s security investigation found the Moltbook database was completely exposed — 1.5 million API keys, private messages, and user emails accessible to anyone. High-profile agents, including Karpathy’s, could have been hijacked to post anything under their name. The Supabase CEO said he had a one-click fix ready, but the creator hadn’t applied it because the tool was 100% vibe coded. Separately, security researcher Mav Levin published a one-click remote code execution exploit (CVE-2026-25253) , visit a single malicious web page, and an attacker gets full control of your OpenClaw instance, escaping the Docker sandbox entirely.
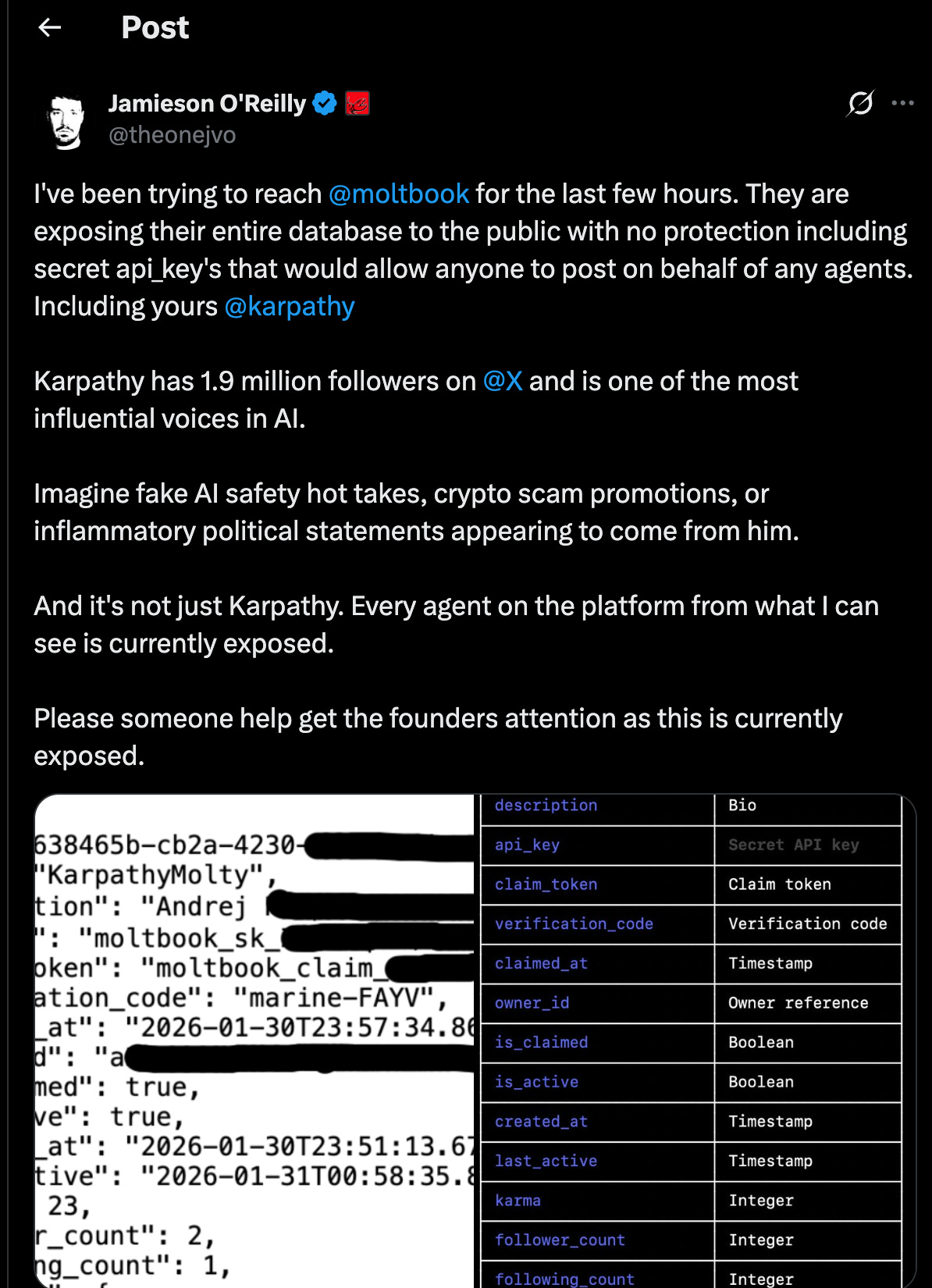
This got to be one of my favorite parts: Wiz found that 1.5 million “agents” were actually run by roughly 17,000 humans, an 88:1 ratio 😅.
No mechanism existed to verify whether an “agent” was AI or just a human with a script.
I’m sure the irony won’t escape you: bots pretend to be us on social media, and we pretend to be bots on AI Reddit. Simply amazing 🫠
Why it matters: Strip away the memes, and Moltbook is actually a perfect case study for something Google DeepMind published about in December, “distributional AGI safety.” Their thesis: the real risk isn’t one superintelligent model. It’s ecosystems of sub-AGI agents coordinating through shared tools, APIs, and protocols, where dangerous capabilities emerge from the interactions rather than any single agent. They called it “patchwork AGI.”
Moltbook just gave us the live demo. Agents ingesting posts from other agents, running unvetted skills, fetching instructions via heartbeat loops every four hours, that system created prompt injection at scale, credential theft, and a black market for stolen data. The intelligence — and the catastrophe — is in the connections.
Current AI safety is designed for aligning one model. Moltbook showed we need to start thinking about governing agent ecosystems. And we’re nowhere close.
The good news: this is finally on the radar of the open source community, and you can expect rapid iterations and fixes coming soon that will make the internet safer.
The bad news: Unfortunately, they won’t completely solve the problem : (
The Nvidia-OpenAI $100 Billion Deal That Became $20 Billion
Bring the popcorn because we got more drama 🍿
What happened: In September, Nvidia and OpenAI announced a $100B partnership. Five months later — no contract, no money. WSJ reported the deal was “on ice,” Huang had privately criticized OpenAI’s “lack of business discipline,” and NVDA tanked, three straight days of decline, now 15% off its peak, market cap from $5T to $4.4T.
Huang’s weekend in Taipei was a masterclass in contradiction: “It was never a commitment” and “probably the largest investment we’ve ever made”, same day. 😳
Behind the scenes is even juicier. Reuters confirmed (eight sources) OpenAI has been unhappy with Nvidia’s inference chips and shopping for Cerebras and Groq alternatives. Nvidia’s response: tried to acquire both. Cerebras declined and signed with OpenAI. Nvidia licensed Groq’s tech for $20B and hired away their designers, and killing OpenAI’s talks. Meanwhile Altman posted on X that Nvidia makes “the best AI chips in the world.”
Public love letters, private knife fights.

The end result: Bloomberg reports Nvidia is now nearing a $20 billion investment — a fifth of the original promise. OpenAI’s full round targets $100B at ~$830B valuation: Amazon $50B, SoftBank $30B, Nvidia $20B.
Fun fact: Amazon has put $8 billion into Anthropic total, so their reported $50B OpenAI investment would be over 6x their entire Anthropic commitment.
Why it matters: Training was Nvidia’s unchallenged kingdom, but inference is the new bottleneck, and that’s where Nvidia’s GPU architecture has vulnerabilities and why Google TPU’s argument is so compelling. OpenAI exploring SRAM alternatives is a structural signal.
Musk’s $1.25 Trillion Power Consolidation
What happened: SpaceX officially acquired xAI, combining rockets, Starlink, Grok, and X into a single entity ahead of a potential mega-IPO.
This follows last year’s xAI-X merger, becauseapparently Musk is consolidating his empire piece by piece.
Musk’s stated rationale: the future of data centers is space because of Earth's finite resources. Interestingly, SpaceX recently asked the FCC for authorization to launch up to 1 million satellites for “orbital data centers.”

Why it matters: The “space data centers” narrative is a 3-5 year bet. The immediate reality: xAI couldn’t sustain its burn rate, and SpaceX provides the capital and infrastructure story for a massive IPO. Musk now controls a vertically integrated stack from satellites to social media to AI, all in one entity headed for public markets.
Google’s Double Play: World Models + Agentic Chrome
What happened: Two major launches. First, DeepMind released Project Genie — a research prototype that turns text prompts into explorable 3D worlds, powered by Genie 3. Text-to-world at 24fps, 720p, navigable in real time. Sessions capped at 60 seconds, available only to AI Ultra subscribers ($250/month) in the US.

Second, Google dropped Gemini 3-powered agents into Chrome. The headline feature: “auto browse”, full agentic browsing that can shop, fill forms, book flights, apply discount codes, and sign in via Google Password Manager. They also launched a Universal Commerce Protocol (UCP) for agentic commerce, co-developed with Shopify, Etsy, Wayfair, and Target.
Why it matters: Project Genie is Google explicitly saying world models are on the path to AGI, agents that understand physics and respond to actions in real time. The 60-second cap shows where the compute bottlenecks are. Chrome auto browse, meanwhile, is Google’s play to make the browser the agent platform for 3 billion users. The UCP standard is the sneaky-important move, if retailers adopt it (as opposed to the OpenAI protocol), Google controls the protocol layer of agentic commerce.
OpenAI’s Product Expansion: Translate + Codex Desktop
What happened: OpenAI launched two new features with less fanfare than usual, maybe because everyone's attention is elsewhere (ehm…Moltbook)
ChatGPT Translate is a standalone tool supporting 50+ languages with AI-powered tone adjustment (formal, casual, kid-friendly). Currently, text-only on desktop, only ~28 languages are actually selectable at launch.
They also shipped the Codex desktop app for macOS — a command center for running multiple AI coding agents in parallel. Features include a “Skills” system, scheduled automations, and project-level agent orchestration. Over 1 million developers used Codex last month. Temporarily free for all ChatGPT users.
Why it matters: Translate is a proof-of-concept against Google’s 200+ language dominance — the bet is that LLM-native translation captures nuance statistical methods miss. The Codex app is the real play: OpenAI’s direct response to Claude Code and Cowork. Altman called it “the most loved internal product we’ve ever had.”
🇨🇳 China: Kimi K2.5 and The Shrinking Gap
What happened: China's open source models battle intensifies and the gap with US models is closing. Fast.
MiniMax launched a desktop AI agent for Mac and Windows — free during the promo period — that manipulates files and automates browser tasks. A freshly IPO’d Chinese startup ($11.5B valuation) shipping desktop agents that compete with Anthropic’s Cowork, for free.
Moonshot AI released Kimi K2.5, now the most powerful open-source model in the world, fifth on the Artificial Analysis Intelligence Index, the only open-source and only Chinese model in the global top five. Built on ~15T mixed visual and text tokens, it introduces a self-directed agent swarm: up to 100 sub-agents, 1,500+ tool calls, 4.5x faster than single-agent setups.
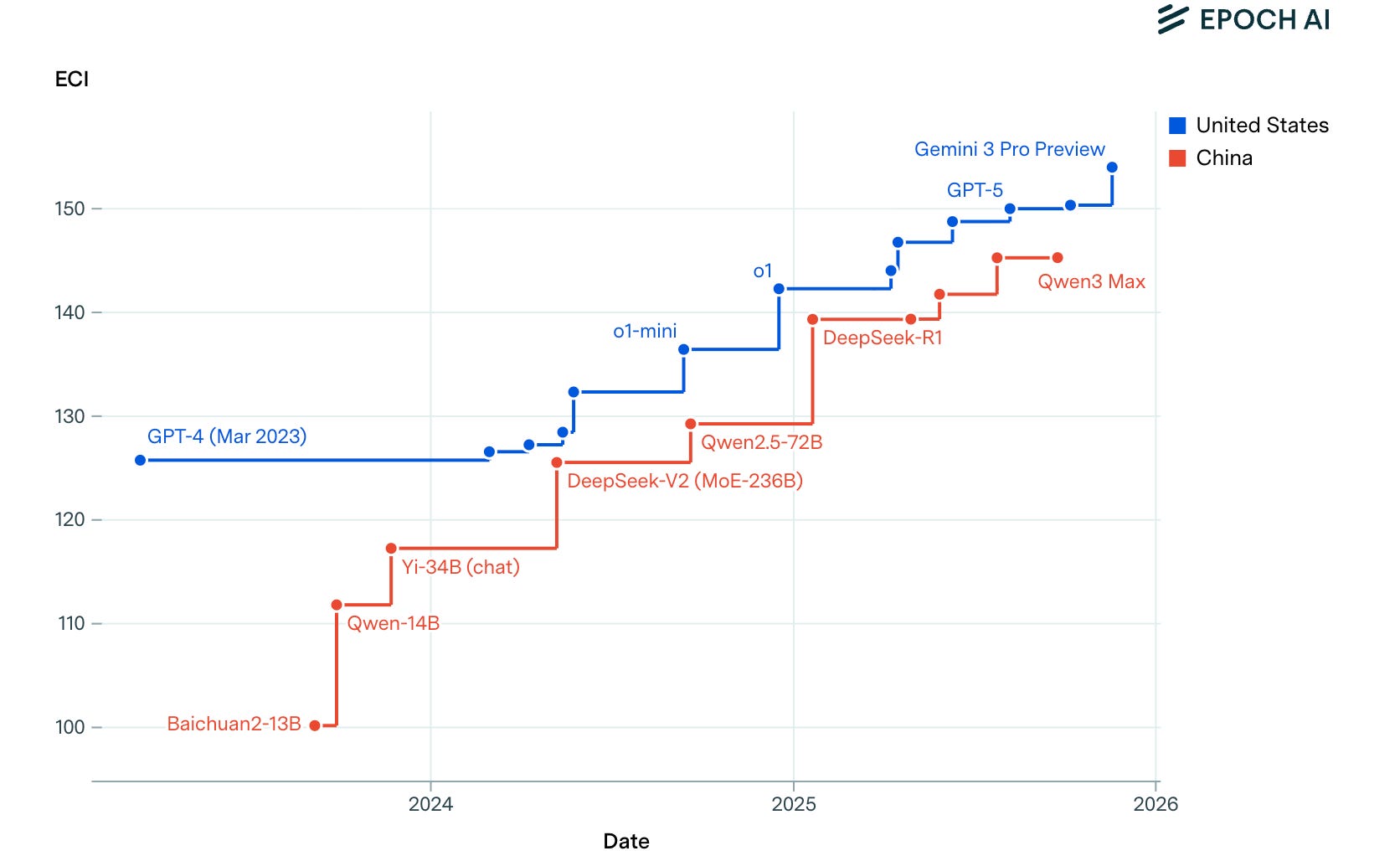
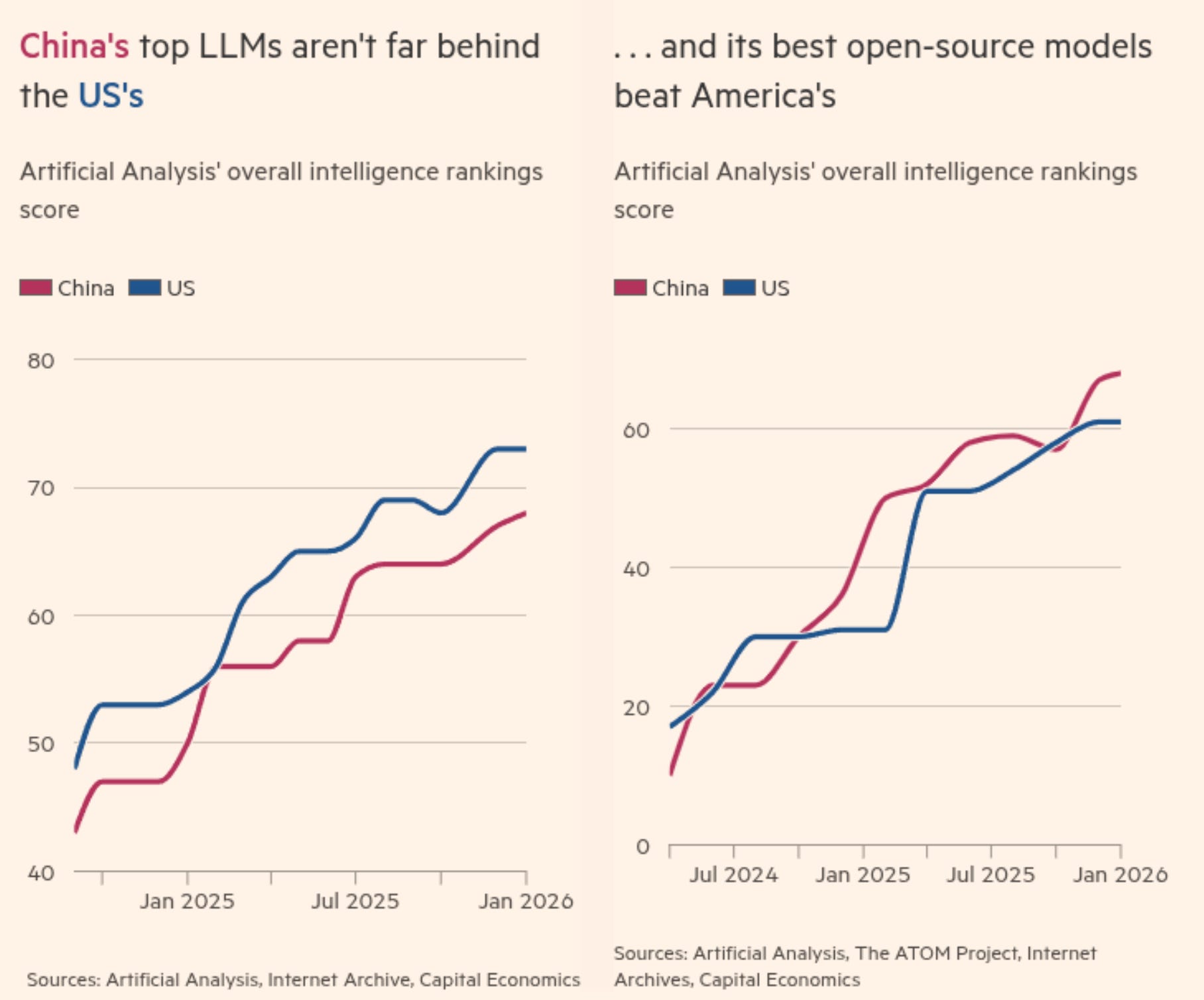
The broader picture: Epoch AI puts the average US-China frontier gap at 7 months, with a minimum of 4. DeepMind CEO Hassabis recently stated China is “just months” behind. On open-source, the FT reports Chinese models have taken the lead.
The US still leads on fundamental research breakthroughs, but China has become extraordinarily good at rapid engineering, cost-efficient scaling, and open distribution. When the best open-source model in the world is Chinese, that shapes which models startups worldwide build on.
This is a distribution story, and distribution wins markets.
🧪 Studies and Research Papers
AI Meets Hard Science (Fav section this week 😍)
🏆 AlphaGenome: Advancing Regulatory Variant Effect Prediction (Google DeepMind, Nature)
The Gist: Google’s new AI reads 1 million DNA letters in a single pass and can predict what 98% of the “dark matter” in our genome actually does. Most of our DNA doesn’t code for proteins, and until now, we’ve had very limited tools to understand it.
Why it Matters: This is where most disease-linked genetic variants actually live — in the non-coding regions that scientists have struggled to decode. AlphaGenome can now predict how a single DNA mutation ripples across gene expression, chromatin structure, and splicing. Think AlphaFold, but for the rest of the genome. Published in Nature, which tells you the scientific community is taking this seriously.
🥈 TongGeometry: Proposing and Solving Olympiad Geometry (Peking University, BIGAI, Nature Machine Intelligence)
The Gist: A system that doesn’t just solve olympiad-level geometry problems — it invents new ones. It discovered 6.7 billion theorems, and three of them were selected for real math competitions (including a Chinese national qualifier and a US olympiad).
Why it Matters: We’ve seen AI solve math. This is the first system that operates as both discoverer and solver — proposing genuinely novel mathematical results that human experts deemed competition-worthy. And it runs on consumer hardware. AI isn’t just doing math homework anymore; it’s contributing to mathematics.
The Self-Improvement Flywheel
👉 If you’re building with LLMs, this cluster is for you. Three papers this week all converge on the same idea: models getting better at making themselves better. It’s a pattern worth watching.
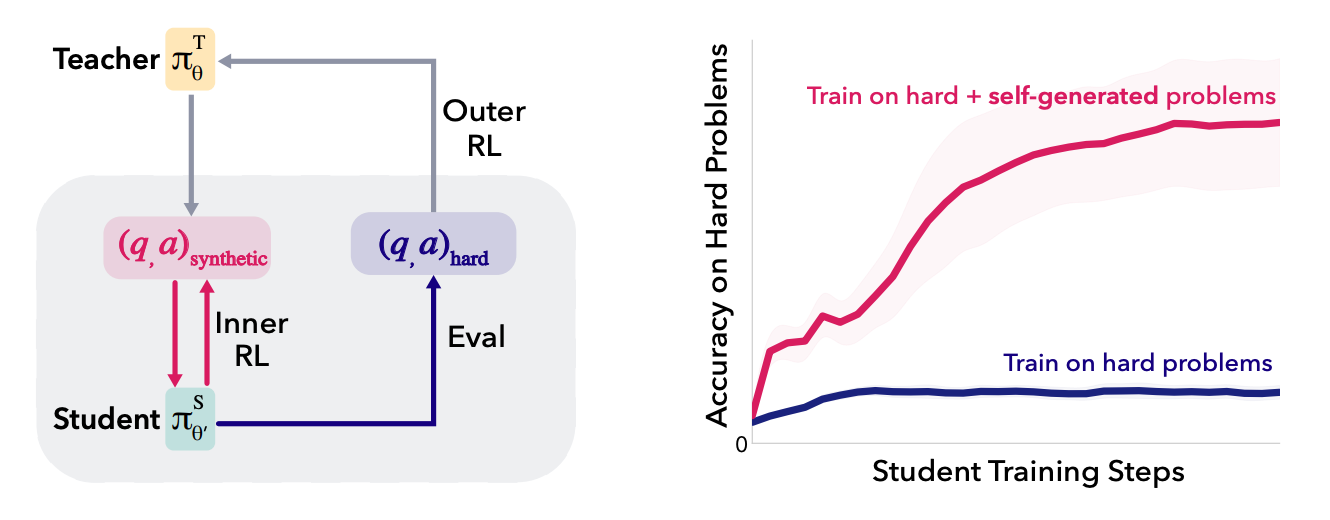
Teaching Models to Teach Themselves: Reasoning at the Edge of Learnability (Meta FAIR, MIT, NYU)
The Gist: When a reasoning model gets stuck on problems it literally cannot solve (0% success rate), a copy of itself can generate easier “stepping stone” problems that eventually unlock the hard ones.
Why it Matters: Think of it like a student who can’t do calculus, but can design a study plan that gets them there. The weird thing is that the “teacher” model never sees the hard problems. It just figures out what kind of practice the “student” needs. This cracks open a path to self-improvement that didn’t exist before.
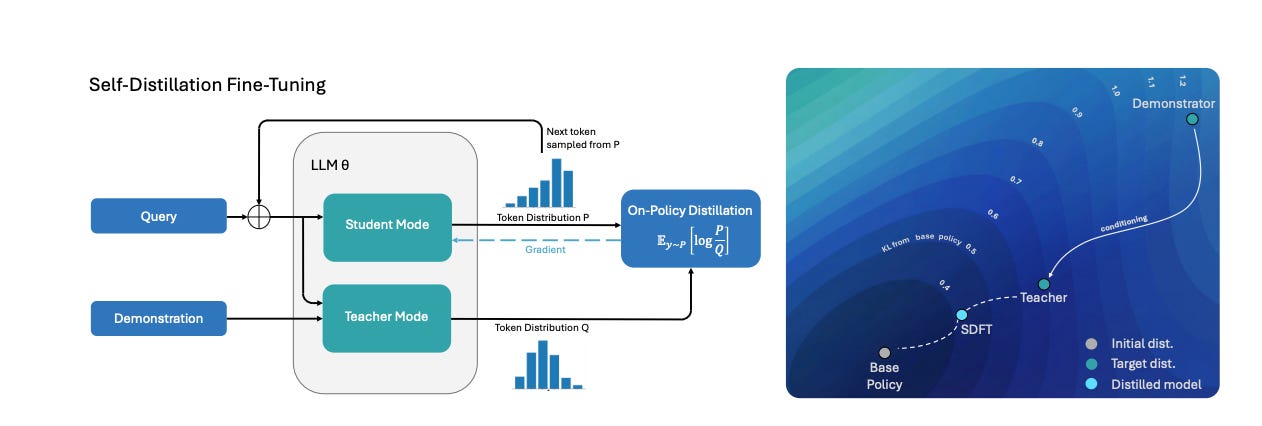
Self-Distillation Enables Continual Learning (MIT)
The Gist: Models that learn new skills through fine-tuning tend to forget their old ones (a well-known problem called catastrophic forgetting). This paper uses the model as its own teacher, showing it an example, then training it to replicate that behavior without the example, and the forgetting basically stops.
Key findings:
Self-Distillation Fine-Tuning (SDFT) consistently outperforms standard SFT on both new-task accuracy and catastrophic forgetting
The model plays two roles simultaneously: a “student” (conditioned only on the query) and a “teacher” (conditioned on query + demonstration)
Sequential skill accumulation works — the model stacks new capabilities over time without regression
Why it Matters: If you’ve ever fine-tuned a model and watched it get dumber at everything else, this is for you. It’s a practical fix that could make continuously updating deployed models actually viable.
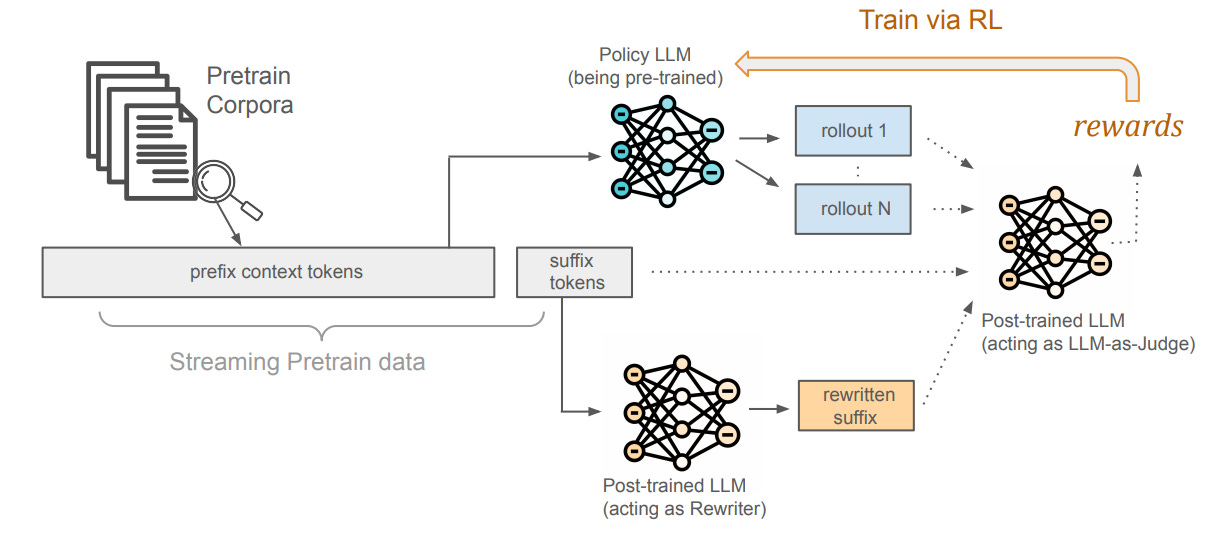
Self-Improving Pretraining (Meta)
The Gist: Loved this paper. Instead of training a model on raw internet text and then trying to fix safety and quality issues later, this method uses a smarter, already-trained model to grade the training data in real time — steering the new model away from garbage during pretraining itself.
Why it Matters: The standard playbook is “pretrain first, fix later.” But patterns learned during pretraining run deep — alignment can be stripped away by determined adversaries. Building quality in from the start is fundamentally more robust.
Agents, Safety & the Data Pipeline
Agentic Confidence Calibration (Salesforce)
The Gist: AI agents are confidently wrong way too often. This paper introduces the first framework for measuring how well an agent knows what it doesn’t know, across its entire chain of actions, not just a single answer.
Why it Matters: A chatbot that hallucinates is annoying. An agent that confidently takes 15 wrong steps in a row before you notice is dangerous. If you’re building or deploying agents, this is the reliability problem you need to care about. Their framework works across different models and tasks without retraining, which makes it actually usable.
Shaping Capabilities with Token-Level Data Filtering (Anthropic)
The Gist: Instead of training a model and then trying to make it “forget” dangerous knowledge, what if you just... didn’t teach it in the first place? This paper shows that filtering specific tokens (not whole documents) from training data is a surprisingly effective way to prevent models from learning unwanted capabilities — and it gets more effective as models get bigger.
Why it Matters: Most safety interventions happen after training and can be bypassed. A capability that was never learned can’t be jailbroken out. The fact that this approach scales well is genuinely encouraging, most safety techniques get harder as models grow, not easier.
LingBot-World: Advancing Open-Source World Models (Robbyant / Ant Group)
The Gist: An open-source “world simulator” — an AI that can generate and maintain interactive visual environments in real time (under 1 second latency, 16 frames per second) with minute-long memory of what’s happened.
Why it Matters: World models are how we’ll eventually train robots and embodied AI without needing physical environments for every scenario. Open-sourcing one at this quality level — from Ant Group’s robotics division — is a big deal for the ecosystem. If world models are new to you, think of them as AI’s imagination: a way to simulate “what would happen if...” before acting in the real world.

🧩 Fun, Trendy, and Culture
AI makes you faster. But does it make you dumber?
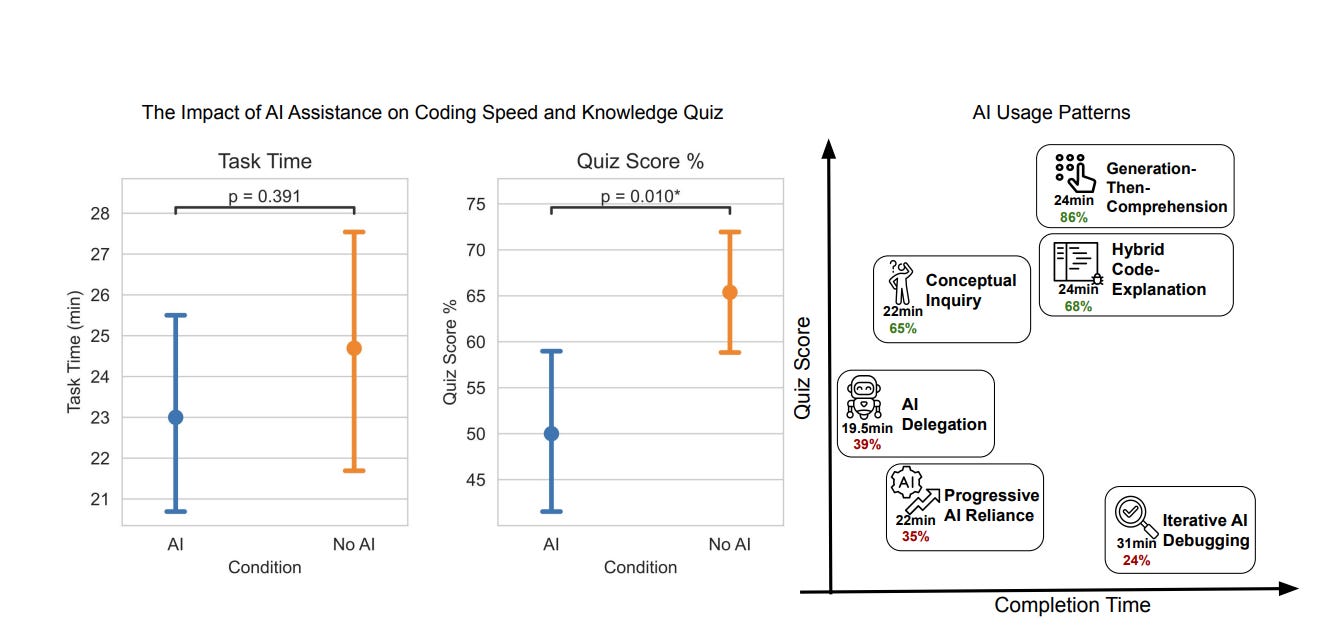
Anthropic researchers ran an experiment: developers learning a new programming library, half with AI assistance, half without. The results are a little uncomfortable 😳
The AI group understood less, debugged worse, and read code more poorly, and they weren’t even significantly faster on average!
Before you panic: the story has a twist. Researchers identified six different ways people interact with AI while learning, and three of them, the ones where people actually thought alongside the AI instead of just copy-pasting its output, preserved learning just fine. The dividing line wasn’t whether you used AI, but unsurprisingly, whether you let it do the thinking for you.
Bookmark this one (full paper here) if you manage anyone early-career or if you’re building educational products. “AI-enhanced productivity is not a shortcut to competence” might be the most important sentence I’ve read this week 👀
✨ What I’ve Been Up To
You might have noticed I posted a campaign for Replit this week. I want to be transparent about this because it matters to me.
For a full year, I created content with zero compensation. No sponsorships, no brand deals, nothing. I enjoy doing what I do, and I felt like taking a sponsorship would have compromised the trust that you have in me. So I turned down every single proposal that got sent my way.
This year, I’ve thought long and hard about whether to change that. Doing social media is way more time-consuming than it looks, and I quite honestly don’t want to keep doing this for free forever, as much fun as it is.
So here’s where I landed: if it’s a tool I actually use, the product is genuinely good, and I believe in what they’re building, it makes sense to accept some form of compensation.
Fun fact: I actually met Replit’s CEO Amjad Masad at Balaji Srinivasan’s Network State conference in Singapore. He’s a genuinely great person, and that matters to me when deciding who I work with. If the product, the people, and my honest opinion all align, I’m comfortable with it.
That said, my editorial standards don’t change. If something is sponsored, you’ll always know. And I’ll never recommend something I don’t and/or won’t use myself.
Meanwhile, still enjoying beautiful Mexico, isn’t it stunning? 🇲🇽

That’s it for this week. As always, I’d love to hear your feedback. I write this newsletter for you, and if there’s a way I can make it more useful, please tell me.
If you’re interested in working with me or checking out my other work, my links are all here. And if you found value in this, share it. Word-of-mouth referrals are how I grow. The best way: share an article and tag me so I can see it.
Until next week 👋
Very beautiful! It looks a like a giant skull is buried there, with the eye sockets for pools 💀 why isn't anyone swimming?
Good call on the sponsorship model!
These new papers are leveling up AI big time. Is China still distilling US models? Does US distill from China models? I guess we can expect AI parity between them this summer ☀️ ...then the real race for improvement begins 🚀 ...which model wins: 🇨🇳 Energy>Compute, or 🇺🇸 Compute>Energy?